

When question comes
еңЁ еҰӮдҪ•з”Ё Nodejs еҲҶжһҗдёҖдёӘз®ҖеҚ•йЎөйқў дёҖж–ҮдёӯпјҢжҲ‘们зҲ¬еҸ–дәҶеҚҡе®ўеӣӯйҰ–йЎөзҡ„ 20 зҜҮж–Үз« ж ҮйўҳпјҢиҫ“еҮәйғЁеҲҶжӢјжҺҘдәҶдёҖдёӘеӯ—з¬ҰдёІпјҡ
var $ = cheerio.load(sres.text); var ans = ''; $('.titlelnk').each(function (index, item) { var $item = $(item); ans += $item.html() + '<br/><br/>'; }); // е°ҶеҶ…е®№е‘ҲзҺ°еҲ°йЎөйқў res.send(ans);йЎөйқўе‘ҲзҺ°иүҜеҘҪпјҡ

дҪҶжҳҜжҹҘзңӢзҪ‘йЎөжәҗд»Јз ҒпјҢеҚҙзңӢеҲ°иҝҷж ·зҡ„жғ…жҷҜпјҡ

д»Җд№Ҳй¬јпјҹжҲ‘们让问йўҳеҶҚжё…жҷ°дәӣпјҢиҜ•зқҖжҠҠзҲ¬иҷ«д»Јз ҒзЁҚеҒҡдҝ®ж”№пјҡ
var $ = cheerio.load(sres.text); var ans = []; $('.titlelnk').each(function (index, item) { var $item = $(item); ans.push($item.html()); }); // е°ҶеҶ…е®№е‘ҲзҺ°еҲ°йЎөйқў res.send(ans);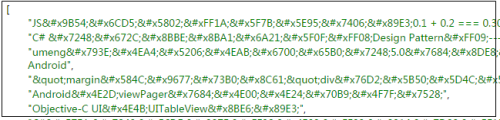
иҝҷиҫ“еҮәзҡ„жҳҜд»Җд№ҲзҺ©ж„Ҹе„ҝпјҹ
д№ұз ҒпјҹдёҚпјҢжҳҜ HTML е®һдҪ“зј–з ҒпјҒ
HTML е®һдҪ“зј–з Ғ
еңЁ HTML дёӯпјҢжҹҗдәӣеӯ—з¬ҰжҳҜйў„з•ҷзҡ„пјҢжҜ”еҰӮдёҚиғҪдҪҝз”Ёе°ҸдәҺеҸ·пјҲ<пјүе’ҢеӨ§дәҺеҸ·пјҲ>пјүпјҢиҝҷжҳҜеӣ дёәжөҸи§ҲеҷЁдјҡиҜҜи®Өдёәе®ғ们жҳҜж ҮзӯҫгҖӮеҰӮжһңеёҢжңӣжӯЈзЎ®ең°жҳҫзӨәйў„з•ҷеӯ—з¬ҰпјҢжҲ‘们еҝ…йЎ»еңЁ HTML жәҗд»Јз ҒдёӯдҪҝз”Ёеӯ—з¬Ұе®һдҪ“пјҲcharacter entitiesпјүгҖӮеҪ“然иҝҳеҸҰдёҖдёӘйҮҚиҰҒеҺҹеӣ пјҢжңүдәӣеӯ—з¬ҰеңЁ ASCII еӯ—з¬ҰйӣҶдёӯжІЎжңүе®ҡд№үпјҢеӣ жӯӨйңҖиҰҒдҪҝз”Ёеӯ—з¬Ұе®һдҪ“жқҘиЎЁзӨәпјҢжҜ”еҰӮдёӯж–ҮгҖӮ
еӯ—з¬Ұе®һдҪ“зұ»дјјиҝҷж ·пјҡ
&entity_name; жҲ–иҖ… &#entity_number;еҰӮйңҖжҳҫзӨәе°ҸдәҺеҸ·пјҢжҲ‘们еҝ…йЎ»иҝҷж ·еҶҷпјҡ< жҲ– <гҖӮеүҚиҖ…пјҲе®һдҪ“еҗҚпјүжҳ“дәҺи®°еҝҶпјҢиҖҢеҗҺиҖ…пјҲе®һдҪ“ж•°еӯ—пјүеңЁжөҸи§ҲеҷЁдёӯзҡ„ж”ҜжҢҒиҫғеҘҪгҖӮ
HTML дёӯеёёи§Ғзҡ„йңҖиҰҒжӣҝжҚўжҲҗеӯ—з¬Ұе®һдҪ“зҡ„еӯ—з¬Ұжңү 4 дёӘпјҢеҲҶеҲ«жҳҜ <гҖҒ>гҖҒ& д»ҘеҸҠ "гҖӮдёәжӯӨпјҢжҲ‘们еҸҜд»Ҙз®ҖеҚ•еҶҷдёӘ escapeHTML еҮҪж•°пјҲдҪҝеҫ—зҪ‘йЎөдёҠеҸҜд»ҘжӯЈзЎ®жҳҫзӨәиҝҷ 4 дёӘеӯ—з¬ҰпјҢиҖҢдёҚдјҡиў«иҜҜи®ӨдёәжҳҜж Үзӯҫпјүпјҡ
function escapeHTML(text) { var replacements= {"<": "<", ">": ">","&": "&", """: """}; return text.replace(/[<>&"]/g, function(character) { return replacements[character]; }); }жӣҙеӨҡе…ідәҺ HTML е®һдҪ“зј–з Ғзҡ„еҶ…е®№еҸҜд»ҘеҸӮиҖғ HTML еӯ—з¬Ұе®һдҪ“
Solution
дёҚд»…жҳҜ "<" ">" иҝҷж ·зҡ„иғҪзј–з ҒпјҢжүҖжңүеӯ—з¬ҰеқҮиғҪзј–з ҒпјҢиҝҷд№ҹжҳҜеҮәзҺ° "д№ұз Ғ" зҡ„еҺҹеӣ гҖӮеңЁж–Үз« ејҖеӨҙзҡ„дҫӢеӯҗдёӯпјҢе…¶е®һе®ғжҠҠиҜҘ target ж ҮзӯҫеҶ…зҡ„жүҖжңүдёңиҘҝпјҲеҢ…жӢ¬дёӯж–ҮпјүйғҪз»ҷзј–з ҒдәҶгҖӮ
иҖҢжңҖејҖе§Ӣзҡ„д»Јз ҒпјҲеӯ—з¬ҰдёІиҫ“еҮәпјүд№ӢжүҖд»ҘжІЎжңү "д№ұз Ғ"пјҢе®Ңе…ЁжҳҜеӣ дёәжөҸи§ҲеҷЁиҮӘеҠЁеё®дҪ и§Јз ҒдәҶгҖӮпјҲеҰӮжһңеӯҳеңЁдәҺ HTML д»Јз ҒдёӯпјҢдјҡиў«иҮӘеҠЁи§Јз Ғпјү
зҹҘйҒ“дәҶеҺҹеӣ пјҢжҲ‘们еҸҜд»Ҙд»ҺдёӨдёӘж–№еҗ‘и§ЈеҶій—®йўҳгҖӮ
йҰ–е…ҲпјҢжҲ‘们еҸҜд»ҘдёҚеҜ№е…¶еҶ…е®№иҝӣиЎҢзј–з ҒгҖӮз”Ё text() ж–№жі•еҸ–д»Ј html() ж–№жі•пјҡ
$('.titlelnk').each(function (index, item) { var $item = $(item); ans.push($item.text()); });еҫҲз®ҖеҚ•е№¶дё”е®ҢзҫҺең°и§ЈеҶідәҶиҝҷдёӘй—®йўҳгҖӮ
еҰӮжһңиҜҙдёҚиғҪд»Һзј–з Ғзҡ„и§’еәҰи§ЈеҶіпјҢжҲ‘们еҸҜд»ҘиҜ•зқҖи§Јз ҒгҖӮ
ж–№жі•дёҖпјҡ
еҲӣе»әз©әж ҮзӯҫпјҢе°Ҷзј–з ҒеҶ…е®№з”Ё html() ж–№жі•еЎһе…ҘпјҢз”Ё text() еҸ–еҮәпјҢиҪ¬жҚўиҝҮзЁӢ让第дёүж–№е®ҢжҲҗпјҲеҪ“然еүҚжҸҗжҳҜиҺ·еҸ–дәҶ $ еҜ№иұЎпјүпјҡ
function htmlDecode(str) { var t = $("<div></div>"); t.html(str); return t.text(); } var $ = cheerio.load(sres.text); var ans = []; $('.titlelnk').each(function (index, item) { var $item = $(item); ans.push(htmlDecode($item.html())); }); // е°ҶеҶ…е®№е‘ҲзҺ°еҲ°йЎөйқў res.send(ans);ж–№жі•дәҢпјҡ
ж №жҚ®зј–з ҒиҪ¬жҚўи§„еҲҷпјҢз”ЁжӯЈеҲҷ decodeпјҡ
function htmlDecode(str) { // дёҖиҲ¬еҸҜд»Ҙе…ҲиҪ¬жҚўдёәж ҮеҮҶ unicode ж јејҸпјҲжңүйңҖиҰҒе°ұж·»еҠ пјҡеҪ“иҝ”еӣһзҡ„ж•°жҚ®е‘ҲзҺ°еӨӘеӨҡ\\\u д№Ӣзұ»зҡ„ж—¶пјү str = unescape(str.replace(/\\u/g, "%u")); // еҶҚеҜ№е®һдҪ“з¬ҰиҝӣиЎҢиҪ¬д№ү // жңү x еҲҷиЎЁзӨәжҳҜ16иҝӣеҲ¶пјҢ$1 е°ұжҳҜеҢ№й…ҚжҳҜеҗҰжңү xпјҢ$2 е°ұжҳҜеҢ№й…ҚеҮәзҡ„第дәҢдёӘжӢ¬еҸ·жҚ•иҺ·еҲ°зҡ„еҶ…е®№пјҢе°Ҷ $2 д»ҘеҜ№еә”иҝӣеҲ¶иЎЁзӨәиҪ¬жҚў str = str.replace(/&#(x)?(\w+);/g, function($, $1, $2) { return String.fromCharCode(parseInt($2, $1? 16: 10)); }); return str; } var $ = cheerio.load(sres.text); var ans = []; $('.titlelnk').each(function (index, item) { var $item = $(item); ans.push(htmlDecode($item.html())); }); // е°ҶеҶ…е®№е‘ҲзҺ°еҲ°йЎөйқў res.send(ans);Encode & Decode
дәӢжғ…еҲ°жӯӨдјјд№ҺеҸҜд»Ҙе‘ҠдёҖж®өиҗҪпјҢжҲ‘们жүҫеҲ°дәҶй—®йўҳзҡ„еҺҹеӣ пјҢд№ҹжүҫеҲ°дәҶи§ЈеҶіеҠһжі•гҖӮдҪҶжҳҜпјҢHTML е®һдҪ“зј–з ҒпјҢе®ғеҲ°еә•жҳҜеҰӮдҪ•зј–з Ғзҡ„пјҹ
жҲ‘们任ж„ҸеҸ–дёҖжқЎж Үйўҳпјҡ
еүҚз«ҜеӨҮеҝҳеҪ• вҖ” IE зҡ„жқЎд»¶жіЁйҮҠзј–з ҒеҗҺдёәпјҡ
前端备忘录 — IE 的条件注释дёӯж–Үзҡ„зј–з Ғз»“жһңејҖеӨҙйғҪжҳҜ &#xгҖӮиҜ•зқҖз”Ё charCodeAt() еҸ–еҫ— "еүҚ" еӯ—зҡ„ unicode зј–з ҒеӨ§е°ҸпјҢ然еҗҺе°Ҷе®ғиҪ¬жҲҗ 16 иҝӣеҲ¶пјҢжӯЈжҳҜ 524d пјҒзңӢжқҘе’Ң escape() зӣёдјјпјҢеҸҲжҳҜдёҖж¬ЎеҚҒе…ӯиҝӣеҲ¶зҡ„иҪ¬жҚўгҖӮ
дҪҶжҳҜиӢұж–ҮеҚҙжІЎжңүиў«иҪ¬пјҢиҝҷзӮ№е’Ң escape() д№ҹзҘһдјјгҖӮе”ҜдёҖдёҚеҗҢзҡ„жҳҜ escape дјҡе°Ҷз©әж јиҪ¬дёә %20пјҢиҖҢ HTML зј–з Ғ并没жңүгҖӮ
иҖҢдё” HTML зј–з Ғз”ҡиҮідјҡе°Ҷ   иҮӘеҠЁзј–з ҒжҲҗ  пјҢиҝҷд№ҹе°ұж„Ҹе‘ізқҖеҰӮжһңиҰҒжүӢеҶҷдёӘ HTML зј–з ҒеҮҪж•°пјҢйңҖиҰҒе°ҶжүҖжңүеӯ—з¬Ұе®һдҪ“зҡ„жҳ е°„йғҪжүҫеҮәжқҘпјҢиҖҢдё”еҜ№дәҺ &XXXX еҪўејҸзҡ„пјҢдјјд№ҺиҝҳиҰҒдҪңдёӘж ЎйӘҢпјҲзЎ®и®ӨжҳҜе®һдҪ“йӣҶиҝҳжҳҜжҷ®йҖҡзҡ„еӯ—з¬ҰдёІпјүгҖӮ
иҖҢ HTML и§Јз ҒеҲҷзӣёеҜ№жқҘиҜҙз®ҖеҚ•еҶҷпјҢеҸӘйңҖе°Ҷ &#xXXX иҝӣиЎҢиҪ¬жҚўпјҢиҜҰз»Ҷд»Јз ҒеҸҜд»ҘеҸӮиҖғ Solution дёҖиҠӮзҡ„жӯЈеҲҷгҖӮ
дәӢе®һдёҠпјҢHTML зј–з Ғ并дёҚдёҖе®ҡиҰҒиҪ¬жҲҗеҚҒе…ӯиҝӣеҲ¶пјҢеҚҒиҝӣеҲ¶д№ҹеҸҜд»ҘгҖӮиҝҳжҳҜд»Ҙ "еүҚ" дёәдҫӢпјҢе®ғзҡ„еҚҒиҝӣеҲ¶ unicode з Ғдёә 21069пјҢе®Ңе…ЁеҸҜд»Ҙз”Ё 前 жқҘд»Јжӣҝ 前гҖӮ
жңҖеҗҺиҝҳжңүдёӨдёӘе®ўжҲ·з«Ҝзҡ„зј–з ҒгҖҒи§Јз ҒеҮҪж•°пјҡ
function HtmlEncode(str) { var t = document.createElement("div"); t.textContent ? t.textContent = str : t.innerText = str; return t.innerHTML; } function HtmlDecode(str) { var t = document.createElement("div"); t.innerHTML = str; return t.textContent || t.innerText; }зңҹзҡ„жҳҜеҗғдёҖе ‘й•ҝдёҖжҷәпјҢд»ҘеҗҺзў°еҲ° "&#x" ејҖеӨҙзҡ„дёҖдәӣзј–з ҒпјҢеҚҒжңүе…«д№қжҳҜ HTML зҡ„е®һдҪ“зј–з ҒпјҢеҶҚд№ҹдёҚз”ЁжӢ…еҝғдәҶпјҒ
Read More:





