

жңүе№ёеҸӮдёҺдәҶдёҖдәӣйўҶеҹҹй©ұеҠЁзҡ„йЎ№зӣ®пјҢиҜ»дәҶдёҖдәӣж–Үз« пјҢд№ҹи§ҒиҜҶдәҶдёҖдәӣдёҚдјҰдёҚзұ»зҡ„жһ¶жһ„пјҢж„ҹи§үеҜ№йўҶеҹҹ й©ұеҠЁжңүдәҶжӣҙиҝӣдёҖжӯҘзҡ„и®ӨиҜҶгҖӮжүҖд»Ҙд»ҠеӨ©и·ҹеӨ§дјҷжҺўи®ЁдёҖдёӢйўҶеҹҹй©ұеҠЁи®ҫи®ЎпјҢеҗҢж—¶д№ҹеҜ№дёҖдәӣжғіиҰҒе®һи·өйўҶеҹҹй©ұеҠЁи®ҫи®ЎеҚҙеҸҲж— еӨ„дёӢжүӢпјҢжҲ–иҖ…дёҖдәӣжӯЈеңЁе®һи·өеҚҙеҸҲиҜҙдёҚдёҠйўҶеҹҹй©ұеҠЁи®ҫи®Ў еҲ°еә•еҘҪеңЁе“Әзҡ„жңӢеҸӢдёҖдәӣжҢҮеј•ж–№еҗ‘гҖӮеҪ“然еҜ№дәҺвҖқйўҶеҹҹй©ұеҠЁи®ҫи®ЎвҖқиҝҷдёӘдё»йўҳиҖҢиЁҖд»ҺжқҘдёҚд№Ҹдәүи®әпјҢжүҖд»ҘеӨ§е®¶еҸҜд»ҘеңЁз•…жүҖж¬ІиЁҖгҖӮ
дёәд»Җд№ҲиҰҒдҪҝз”ЁйўҶеҹҹй©ұеҠЁи®ҫи®Ўпјҹ
д»ҺEric Evansзҡ„гҖҠйўҶеҹҹй©ұеҠЁи®ҫи®ЎпјҡиҪҜд»¶ж ёеҝғеӨҚжқӮжҖ§еә”еҜ№д№ӢйҒ“гҖӢдёҖд№Ұзҡ„д№ҰеҗҚе°ұеҸҜд»ҘзңӢеҮәиҝҷдёҖж–№жі•и®әжҳҜдёәдәҶи§ЈеҶіиҪҜд»¶ж ёеҝғеӨҚжқӮжҖ§зҡ„гҖӮд№ҹе°ұжҳҜиҜҙиҪҜ件дёҡеҠЎи¶ҠжқҘи¶ҠеӨҚжқӮдәҶпјҢйўҶеҹҹй©ұеҠЁи®ҫи®ЎеҸҜд»Ҙи®©дәӢжғ…еҸҳеҫ—з®ҖеҚ•гҖӮиҖҢе®һйҷ…жғ…еҶөжҳҜпјҡйўҶеҹҹй©ұеҠЁи®ҫи®Ўзҡ„й—Ёж§ӣеҫҲй«ҳпјҢжІЎжңүеҫҲж·ұеҺҡзҡ„йқўеҗ‘еҜ№иұЎзј–з ҒиғҪеҠӣеҮ д№ҺдёҚеҸҜиғҪе®һи·өжҲҗеҠҹгҖӮ
иҝҷдёҖиҜҙжі•жҳҜеҗҰзҹӣзӣҫе‘ўпјҹMartin FowlerеңЁPoEAAдёҖд№Ұдёӯз»ҷдәҶжңүеҠӣзҡ„и§ЈйҮҠпјҡ

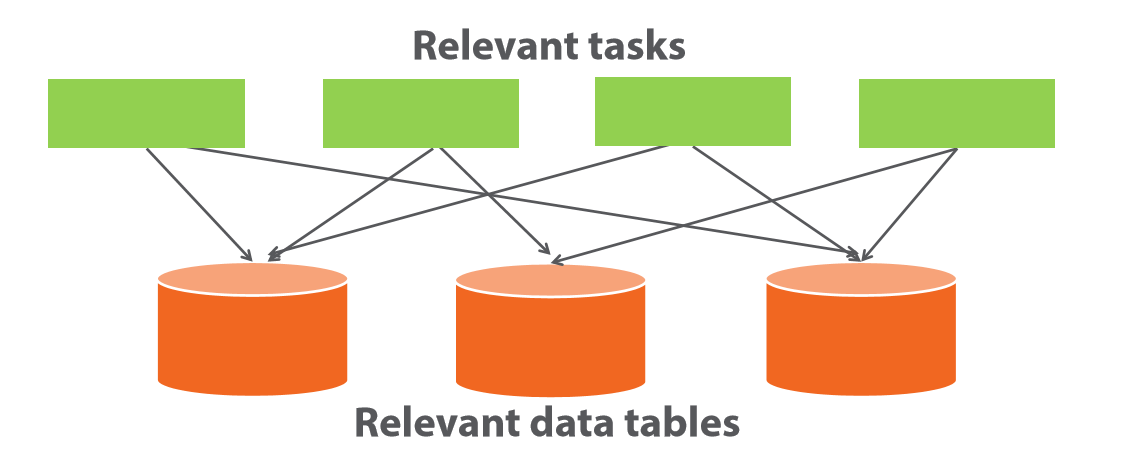
жҲ‘们жҠҠдёүеұӮжһ¶жһ„зӯүйҷӨдәҶйўҶеҹҹй©ұеҠЁд№ӢеӨ–зҡ„жһ¶жһ„ж–№ејҸйғҪеҸҜд»ҘеҪ’зәідёәд»Ҙж•°жҚ®дёәдёӯеҝғзҡ„жһ¶жһ„ж–№ејҸпјҢеңЁеӣҫдёӯжҳҜй»‘иүІзҡ„зІ—е®һзәҝгҖӮ
йўҶеҹҹй©ұеҠЁи®ҫи®ЎеңЁеӣҫдёӯжҳҜз»ҝиүІзҡ„зІ—е®һзәҝгҖӮ
еҪ“иҪҜ件еңЁејҖеҸ‘еҲқжңҹпјҢд»Ҙж•°жҚ®дёәдёӯеҝғй©ұеҠЁзҡ„жһ¶жһ„ж–№ејҸйқһеёёе®№жҳ“дёҠжүӢпјҢдҪҶжҳҜйҡҸзқҖдёҡеҠЎзҡ„еўһй•ҝе’ҢйЎ№зӣ®зҡ„жҺЁиҝӣпјҢиҪҜ件ејҖеҸ‘е’Ңз»ҙжҠӨйҡҫеәҰжҖҘеү§еҚҮй«ҳгҖӮ
йўҶеҹҹй©ұеҠЁи®ҫи®ЎеҲҷеңЁйЎ№зӣ®еҲқжңҹе°ұеӨ„еңЁдёҖдёӘжҜ”иҫғйҡҫд»ҘдёҠжүӢзҡ„дҪҚзҪ®пјҢдҪҶжҳҜйҡҸзқҖдёҡеҠЎзҡ„еўһй•ҝе’ҢйЎ№зӣ®зҡ„жҺЁиҝӣпјҢиҪҜ件ејҖеҸ‘е’Ңз»ҙжҠӨйҡҫеәҰе№іж»‘дёҠеҚҮгҖӮ
иҝҷе№…еӣҫеҪўиұЎзҡ„и§ЈйҮҠдәҶйўҶеҹҹй©ұеҠЁи®ҫи®Ўе’Ңдј з»ҹзҡ„иҪҜ件ејҖеҸ‘жЁЎејҸдёӨиҖ…еңЁиҪҜ件ејҖеҸ‘иҝҮзЁӢдёӯи§ЈеҶіеӨҚжқӮжҖ§д№Ӣй—ҙзҡ„е·®ејӮгҖӮ
йўҶеҹҹй©ұеҠЁи®ҫи®Ўзҡ„ж ёеҝғжҳҜд»Җд№Ҳпјҹ
йЎҫеҗҚжҖқд№үпјҢйўҶеҹҹй©ұеҠЁи®ҫи®Ўзҡ„ж ёеҝғжҳҜйўҶеҹҹжЁЎеһӢпјҢиҝҷдёҖж–№жі•и®әеҸҜд»ҘйҖҡдҝ—зҡ„зҗҶи§Јдёәе…ҲжүҫеҲ°дёҡеҠЎдёӯзҡ„йўҶеҹҹжЁЎеһӢпјҢд»ҘйўҶеҹҹжЁЎеһӢдёәдёӯеҝғй©ұеҠЁйЎ№зӣ®зҡ„ејҖеҸ‘гҖӮиҖҢйўҶеҹҹжЁЎеһӢзҡ„и®ҫи®ЎзІҫй«“еңЁдәҺйқўеҗ‘еҜ№иұЎеҲҶжһҗпјҢеңЁдәҺеҜ№дәӢзү©зҡ„жҠҪиұЎиғҪеҠӣпјҢдёҖдёӘйўҶеҹҹй©ұеҠЁжһ¶жһ„еёҲеҝ…然жҳҜдёҖдёӘйқўеҗ‘еҜ№иұЎеҲҶжһҗзҡ„еӨ§еёҲгҖӮ
еңЁ йқўеҗ‘еҜ№иұЎзј–зЁӢдёӯ讲究е°ҒиЈ…пјҢ讲究и®ҫи®ЎдҪҺиҖҰеҗҲпјҢй«ҳеҶ…иҒҡзҡ„зұ»гҖӮиҖҢеҜ№дәҺдёҖдёӘиҪҜ件е·ҘзЁӢжқҘи®ІпјҢд»…д»…еҸӘйқ зұ»зҡ„и®ҫи®ЎжҳҜдёҚеӨҹзҡ„пјҢжҲ‘们йңҖиҰҒжҠҠзҙ§еҜҶиҒ”зі»еңЁдёҖиө·зҡ„дёҡеҠЎи®ҫи®ЎдёәдёҖдёӘйўҶ еҹҹжЁЎеһӢпјҢи®©йўҶеҹҹжЁЎеһӢеҶ…йғЁйҡҗи—ҸдёҖдәӣз»ҶиҠӮпјҢиҝҷж ·дёҖжқҘйўҶеҹҹжЁЎеһӢе’ҢйўҶеҹҹжЁЎеһӢд№Ӣй—ҙе…ізі»е°ұдјҡеҸҳеҫ—з®ҖеҚ•гҖӮиҝҷдёҖжҖқжғіжңүж•Ҳзҡ„йҷҚдҪҺдәҶеӨҚжқӮзҡ„дёҡеҠЎд№Ӣй—ҙеҚғдёқдёҮзј•зҡ„иҖҰеҗҲе…ізі»гҖӮ
дёӢеӣҫдёәвҖңд»Ҙж•°жҚ®дёәдёӯеҝғзҡ„жһ¶жһ„жЁЎејҸвҖқпјҢиЎЁе’ҢиЎЁд№Ӣй—ҙе…ізі»й”ҷз»јеӨҚжқӮпјҡ
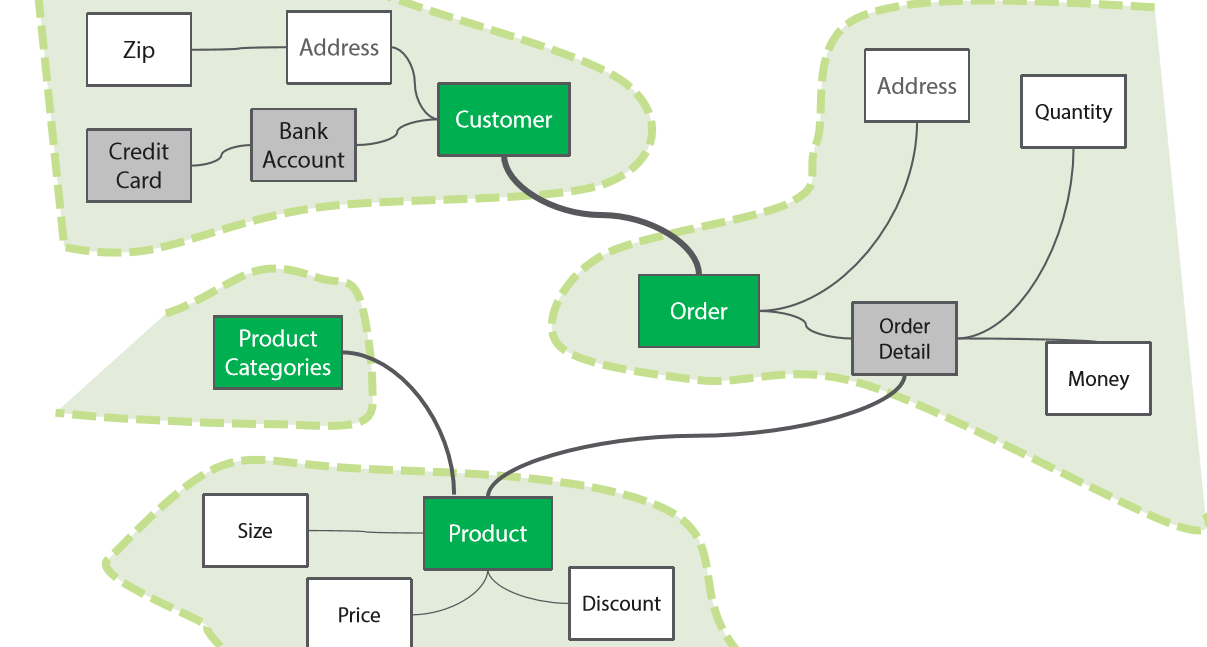
дёӢеӣҫжҳҜвҖңйўҶеҹҹжЁЎеһӢвҖқпјҡйўҶеҹҹе’ҢйўҶеҹҹд№Ӣй—ҙеҸӘеӯҳеңЁеӨ§зІ’еәҰзҡ„жҺҘеҸЈе’ҢдәӨдә’пјҡ
еҲқжңҹеӯҰд№ DDDзҡ„жңӢеҸӢдёҖе®ҡдёҚдјҡй”ҷиҝҮEric EvansеҶҷзҡ„гҖҠйўҶеҹҹй©ұеҠЁи®ҫи®ЎпјҡиҪҜд»¶ж ёеҝғеӨҚжқӮжҖ§еә”еҜ№д№ӢйҒ“гҖӢпјҢиҝҷжң¬д№ҰеҗҚж°”еҫҲеӨ§пјҢд№ҹжҳҜеҫҲеӨҡдәәе…Ҙй—ЁйўҶеҹҹй©ұеҠЁи®ҫи®Ўзҡ„йҰ–йҖүиҜ»зү©пјҢиҝҷжң¬д№ҰжҸҗеҲ°дәҶйўҶеҹҹй©ұеҠЁи®ҫи®Ўдёӯзҡ„дёҖдәӣжҰӮеҝөпјҡRepositoryпјҢDomainпјҢValueObjectзӯүгҖӮдҪҶжҳҜиҝҷжң¬д№ҰеҗҢж—¶з»ҷеҲқеӯҰиҖ…з»ҷдәҶдёҖдёӘй”ҷиҜҜзҡ„еј•еҜјпјҡжңүдәәиҜҜи®ӨдёәйЎ№зӣ®жһ¶жһ„дёӯеҠ е…Ҙ***RepositoryпјҢ***DomainпјҢ***ValueObjectе°ұеҸҳжҲҗдәҶDDDжһ¶жһ„гҖӮеҰӮжһңжІЎжңүжӮҹеҮәе…¶зІҫй«“е°ұеңЁйЎ№зӣ®дёӯеҠ е…ҘиҝҷдәӣжҰӮеҝөе……е…¶йҮҸд№ҹдёҚиҝҮжҳҜдёӘдёүеұӮжһ¶жһ„пјҢеҸҚд№ӢеҜ№дәҺдёҖдёӘйқўеҗ‘еҜ№иұЎеҲҶжһҗзҡ„й«ҳжүӢиҖҢиЁҖпјҢжІЎжңүиҝҷдәӣ组件д№ҹеҸҜд»Ҙе®һзҺ°йўҶеҹҹй©ұеҠЁи®ҫи®ЎгҖӮ
д»ҘRepositoryзҡ„и®ҫи®ЎдёәдҫӢпјҢжҲ‘з»ҸеёёзңӢеҲ°дёҖдәӣж–Үз« дёӯеҜ№IRepositoryе®ҡд№үдёәпјҡ
|
1
2
3
4
5
6
7
8
|
public interface IRepository<TAggregateRoot>{В В В В TAggregateRoot Get(int id);В В В В void Remove(TAggregateRoot aggregateRoot);В В В В void Update(TAggregateRoot aggregateRoot);В В В В //What's this?В В В В TAggregateRoot Where(Expression<Func<TAggregateRoot, bool>> filter); |
|
1
2
|
В В В В //вҖҰ} |
иҜ·и®°дҪҸйўҶеҹҹй©ұеҠЁи®ҫи®ЎжҳҜд»ҘйўҶеҹҹжЁЎеһӢдёәеҹәжң¬еҚ•дҪҚпјҢд№ҹе°ұж„Ҹе‘ізқҖеңЁIRepository<TAggregate>жҺҘеҸЈдёӯпјҢеҸӘжңүGet(int id)пјҢUpdate(TAggregateRoot aggregate)пјҢRemove(TAggregateRoot aggregate)иҝҷдёүдёӘжҺҘеҸЈжҳҜжңүж„Ҹд№үзҡ„гҖӮ Where(Expression<Func<TAggregateRoot,bool>> filter)иҝҷдёҖе®ҡд№үжҡҙйңІдәҶдҪ жҳҜеңЁеңЁиҝӣиЎҢеҚ•иЎЁж“ҚдҪңпјҢеҜ№дәҺйўҶеҹҹжЁЎеһӢжқҘи®ІжІЎжңүжҹҘиҜўдёҖиҜҙгҖӮ
иҖҢеҜ№дәҺIUserRepositoryиҝҷж ·дёҖдёӘзЁҚеҫ®е…·дҪ“зҡ„жҺҘеҸЈе®ҡд№үпјҡ
|
1
2
3
4
5
6
7
|
public interface IUserRepository : IRepository<User>{В В В В //What's this?В В В В List<Rule> GetRules(int id);В В В В //....} |
дёҖдёӘIUserRepositoryд»Қ然жҳҜдёҖдёӘRepositoryпјҢд»–д№ҹеҸӘиғҪд»ҘUserиҒҡеҗҲж №дёәеҚ•дҪҚиҝӣиЎҢж“ҚдҪңгҖӮж–№жі• List<Rule> GetRules(int id)е°ҶжӯӨRepositoryжү“еӣһдәҶеҺҹеҪўпјҢиҝҷдёҚеҶҚжҳҜдёҖдёӘRepositoryпјҢиҝҷжҳҜдёҖдёӘDALгҖӮ
жӯЈзЎ®зҡ„е®һзҺ°ж–№ејҸпјҡ
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
public class User:AggregateRoot{В В В В public List<Rule> GetRules()В В В В {В В В В В В В В return null;В В В В } }public class LeavingManageService{В В В В private readonly IUserRepository _userRepository;В В В В public UserService(IUserRepository userRepository)В В В В {В В В В В В В В _userRepository = userRepository;В В В В }В В В В public void ApproveRequest(int userId)В В В В {В В В В В В В В var user = _userRepository.Get(userId);В В В В В В В В var rules = user.GetRules();В В В В В В В В //......В В В В }} |
иҝҷж®өд»Јз ҒдҪ“зҺ°дәҶUserдҪңдёәдёҖдёӘйўҶеҹҹжЁЎеһӢпјҢд»–жӢҘжңүиҮӘе·ұзҡ„иҒҢиҙЈе’ҢиғҪеҠӣгҖӮ
еҰӮдҪ•ејҖе§Ӣе®һи·өйўҶеҹҹй©ұеҠЁи®ҫи®Ўпјҹ
жӯЈеҰӮжң¬ж–ҮйҖҡзҜҮжүҖиҜҙпјҢйўҶеҹҹй©ұеҠЁи®ҫ计讲究зҡ„жҳҜйўҶеҹҹжЁЎеһӢзҡ„еҲҶжһҗе’ҢеҜ№дәӢзү©зҡ„жҠҪиұЎпјҢд»ҺжқҘжІЎжңүжҸҗиө·иҝҮж•°жҚ®еҰӮдҪ•еӯҳеҸ–иҝҷдёӘиҜқйўҳпјҢиЁҖдёӢд№Ӣж„ҸеңЁйўҶеҹҹй©ұеҠЁи®ҫи®ЎдёӯпјҢжҲ‘们дёҚе…іеҝғиҝҮж•°жҚ®еҰӮдҪ•еӯҳеҸ–пјҢжҖҺд№Ҳж ·еҶҷlinqж•ҲзҺҮй«ҳпјҢдҪҝз”ЁжҮ’еҠ иҪҪиҝҳжҳҜincludeпјҢиҝҷдәӣе®һзҺ°з»ҶиҠӮдјҡе°ҶдҪ еёҰе…Ҙдј з»ҹзҡ„дёүеұӮжһ¶жһ„жЁЎејҸдёӯгҖӮ
еңЁйўҶеҹҹй©ұеҠЁи®ҫи®Ўдёӯе…Ҳи®ҫи®ЎйўҶеҹҹжЁЎеһӢпјҢжҺҘзқҖеҶҷDomainйҖ»иҫ‘пјҢиҮідәҺж•°жҚ®еә“пјҢд»…д»…жҳҜз”ЁжқҘеӯҳеӮЁж•°жҚ®зҡ„е·Ҙе…·гҖӮдҪҝз”Ёdatabase firstйӮЈдёҚеҸ«йўҶеҹҹй©ұеҠЁи®ҫи®ЎпјҢеҫҲжҳҺжҳҫдҪ е…Ҳи®ҫи®Ўзҡ„иЎЁз»“жһ„иҝҳи°Ҳд»Җд№ҲйўҶеҹҹй©ұеҠЁпјҹжӣҙдёҚиҰҒеј•е…Ҙж•°жҚ®еә“зӢ¬жңүзҡ„жҠҖжңҜпјҢдҫӢеҰӮи§ҰеҸ‘еҷЁпјҢеӯҳеӮЁиҝҮзЁӢзӯүгҖӮж•°жҚ®еә“йҷӨдәҶеӯҳеӮЁж•°жҚ®еӨ–пјҢ е…¶дҪҷдёҖеҲҮйҖ»иҫ‘йғҪжҳҜDomainйҖ»иҫ‘гҖӮ
жҲ‘们дёҚеҰЁд»ҘеӨ§е®¶йғҪжҜ”иҫғзҶҹжӮүзҡ„еҢ»йҷўй—ЁиҜҠзңӢз—…жөҒзЁӢдёҫдёӘдҫӢеӯҗпјҢзңӢзңӢеҰӮдҪ•ејҖе§Ӣе®һи·өйўҶеҹҹй©ұеҠЁи®ҫи®Ўпјҡ
жҲ‘们жҡӮдё”и®ӨдёәдёҖдёӘй—ЁиҜҠзңӢз—…жөҒзЁӢе°ұжҳҜдёҖдёӘе®Ңж•ҙзҡ„йўҶеҹҹжЁЎеһӢпјҢжӯӨж—¶дҪ иҰҒеҝҳжҺүж•°жҚ®еә“пјҢдёҚиҰҒеҶҚжғіиЎЁз»“жһ„еҰӮдҪ•и®ҫи®ЎпјҢиҖҢжҳҜе°ұиҝҷдёҖйўҶеҹҹжЁЎеһӢиҝӣиЎҢжҠҪиұЎпјҡ
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
public class OutPatientProcess:AggregateRoot{В В В В public Registration _registration { get; private set; }//жҢӮеҸ·еҚ•В В В В private List<Examination> _examinations;В В В В public IReadOnlyList<Examination> Examinations => _examinations.AsReadOnly();//еҢ–йӘҢеҚ•В В В В public Prescription Prescription { get; private set; }//еӨ„ж–№В В В В public DateTime ConsultaionTime { get; private set; }//жҺҘиҜҠж—¶й—ҙВ В В В public Doctor Doctor { get; private set; }//жҺҘиҜҠеҢ»еёҲВ В В В //ејҖе§ӢдёҖдёӘй—ЁиҜҠжІ»з–—иҝҮзЁӢВ В В В public void StartProcess(Registration registration)В В В В {В В В В В В В В _registration = registration;В В В В В В В В InquireSymptoms();В В В В В В В В WriteOutExamination();В В В В В В В В WritePrescription();В В В В }В В В В //иҜўй—®з—…дәәз—…жғ…В В В В public void InquireSymptoms()В В В В {В В В В В В В В В В В }В В В В //ејҖз«ӢеҢ–йӘҢеҚ•В В В В private void WriteOutExamination()В В В В {В В В В В В В В _examinations.Add(new Examination());В В В В }В В В В //еЎ«еҶҷеӨ„ж–№В В В В private void WritePrescription()В В В В {В В В В В В В В В В В В }} |
жҲ‘们жҡӮдё”дёҚи®Ёи®әиҝҷдёҖжЁЎеһӢжҳҜеҗҰз¬ҰеҗҲзңҹе®һеңәжҷҜпјҢдҪҶжҳҜиҝҷдёӘдҫӢеӯҗеёҰдҪ иҝҲе…ҘдәҶйўҶеҹҹй©ұеҠЁи®ҫи®Ўзҡ„第дёҖжӯҘпјҢеҗҢж—¶иҝҷдёӘдҫӢеӯҗд№ҹеҗ‘дҪ еұ•зӨәдәҶиҪҜ件ејҖеҸ‘жҳҜеҸҜд»ҘдёҚз”Ёе…Ҳи®ҫи®Ўж•°жҚ®еә“ зҡ„гҖӮеҪ“дҪ еҶҷеҘҪжүҖжңүзҡ„DomainйҖ»иҫ‘еҗҺеҶҚиҖғиҷ‘жҠҠиҝҷдёӘзұ»жҢҒд№…еҢ–еңЁж•°жҚ®еә“дёӯе°ұеҘҪдәҶгҖӮеңЁжҲ‘зңјдёӯпјҢж•°жҚ®еә“д»…д»…жҳҜдёҖдёӘдҝқеӯҳж•°жҚ®зҡ„дёңиҘҝпјҢдёҚиҰҒжҠҠд»–иҝҮж—©зҡ„иҖҰеҗҲеңЁд»Јз ҒдёӯгҖӮ иҝҷдёҖејәи°ғдәҶеҫҲеӨҡйҒҚзҡ„и§ӮзӮ№еҪұе“ҚзқҖдҪ иғҪеҗҰжҲҗеҠҹе®һи·өDDDгҖӮ
CQRSжһ¶жһ„еұ•жңӣ
иҜқиҷҪиҝҷж ·иҜҙпјҢдҪҶжҳҜ既然дҪ еңЁдҪҝз”Ёе…ізі»ж•°жҚ®еә“пјҢжңүдәәе°ұе…ҚдёҚдәҶи·ҹдҪ жҸҗиө·жҖ§иғҪжҖҺд№ҲдјҳеҢ–иҝҷж ·зҡ„иҜқйўҳгҖӮиҝҷд№ҹжҳҜдј з»ҹORM+е…ізі»ж•°жҚ®е®һзҺ°йўҶеҹҹй©ұеҠЁи®ҫи®Ўзҡ„зЎ¬дјӨпјҢзү№еҲ« жҳҜеҪ“дҪ зҡ„йўҶеҹҹжЁЎеһӢScopeи®ҫи®ЎиҝҮеӨ§пјҢж„Ҹе‘ізқҖTAggregate Get(int id)ж“ҚдҪңжҜҸж¬ЎйғҪиҰҒе…іиҒ”дёҖе ҶиЎЁеҮәжқҘпјҢзү№еҲ«жҳҜжңүдәәи®ҫи®Ўж•°жҚ®е–ңж¬ўйҒөе®Ҳ第NиҢғејҸиҝҷз§Қеҹәжң¬е°ұжІЎиҫҷдәҶпјҲжҲ‘жҜ”иҫғе–ңж¬ўиЎЁз»“жһ„еҶ—дҪҷи®ҫи®ЎпјүпјҢдёҚеҫ—дёҚиҜҙеҲ°жңҖеҗҺз”ұдәҺж•°жҚ®еә“зҡ„еӯҳеӮЁ жҖ§иғҪй—®йўҳжҲ‘们еҸҲдёҖж¬Ўе°Ҷж•°жҚ®еә“зәіе…ҘеҲ°дәҶиҖғиҷ‘иҢғеӣҙгҖӮ
и§ЈеҶіиҝҷдёҖй—®йўҳзҡ„ж–№жЎҲжҳҜCQRSжһ¶жһ„пјҢ Queryз«Ҝеҗ„з§Қзј“еӯҳе’ҢNosqlпјҢйЎәдҫҝжҠҠжҗңзҙўеј•ж“Һд№ҹз”ЁдёҠпјҢи®©дҪ зҡ„иҪҜ件йЈһеҘ”иө·жқҘгҖӮиҝҷдёҖжһ¶жһ„и§ЈиҖҰдәҶж•°жҚ®еә“ж“ҚдҪңпјҢдҪ еҹәжң¬жІЎжңүжңәдјҡи·ҹж•°жҚ®еә“жү“дәӨйҒ“并且иҝҳи§ЈеҶідәҶж•°жҚ®еӯҳеӮЁзҡ„жҖ§иғҪй—®йўҳгҖӮ
иҝҷдёҖиҝӣеҢ–иҝҮзЁӢд№ҹи§ЈејҖдәҶдёҖдәӣдәәзҡ„з–‘иҷ‘пјҢдёәд»Җд№Ҳд»ҺеҲҡејҖе§ӢеҶҷд»Јз Ғе°ұејҖе§ӢеӯҰд№ еҗ„з§Қи®ҫи®ЎжЁЎејҸпјҢдҪҶжҳҜд»ҺжқҘжІЎжңүжңәдјҡдҪҝз”ЁиҝҮпјҹеӣ дёәдҪ жүҖеҶҷзҡ„д»Јз Ғж— ж—¶ж— еҲ»дёҚиҖҰеҗҲзқҖж•°жҚ®еә“иҝҷдёҖвҖңжҜ’зҳӨвҖқпјҢиҖҢж•°жҚ®еә“ж“ҚдҪңдҪңдёәдёҖз§Қе®һзҺ°з»ҶиҠӮжҺәжқӮеңЁдҪ зҡ„д»Јз ҒдёӯпјҢжүҖд»ҘйўҶеҹҹй©ұеҠЁи®ҫи®ЎдёәжӯӨиҖҢз”ҹпјҢдҪ еҮҶеӨҮеҘҪдәҶеҗ—пјҹ






